The world's largest and meanest scientific instrument
just paired up world's fastest and baddest computing machine, thanks to an I/O
system overhall. According to a recent blog
post from Swiss National Supercomputing Center (CSCS), the supercomputer
"Phoenix" that is serving the number crunching for the ATLAS LHC detector, just
set a world record in the speed of which data is served to the full compute
cluster.
Here is the background on the ATLAS dector and its associated data storage and analysis challenge:
ATLAS (A Toroidal LHC Apparatus) is one of the seven particle detector experiments (ALICE, ATLAS, CMS, TOTEM, LHCb, LHCf and MoEDAL) constructed at the Large Hadron Collider (LHC), a new particle accelerator at the European Organization for Nuclear Research (CERN) in Switzerland.
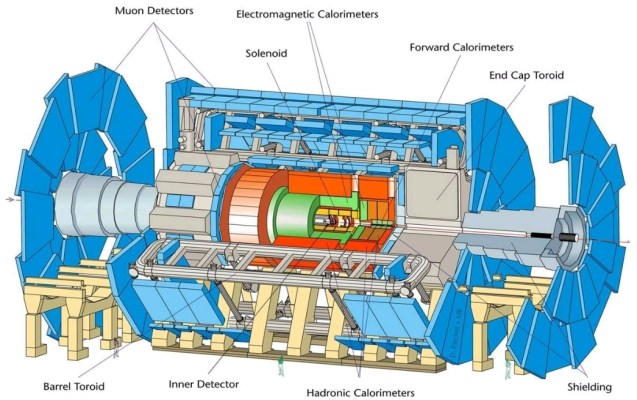
The detector generates unmanageably large amounts of raw data, about 25 megabytes per event (raw; zero suppression reduces this to 1.6 MB) times 23 events per beam crossing, times 40 million beam crossings per second in the center of the detector, for a total of 23 petabyte/second of raw data. Offline event reconstruction is performed on all permanently stored events, turning the pattern of signals from the detector into physics objects, such as jets, photons, and leptons. Grid and HPC are extensively used for event reconstruction, allowing the parallel use of university and laboratory computer networks throughout the world for the CPU-intensive task of reducing large quantities of raw data into a form suitable for physics analysis.
It has been a long journey and struggle for ATLAS analysis sites worldwide to find a balance of cost and performance with their HPC infrastructure, suc as the storage system and architecure that can sustain high demand of data I/O and reliability. As more workloads are outstripping the capability of local hard drive, some sites have started to investiage parallel file systems that can provide fast I/O storage from low-medium cost disks.
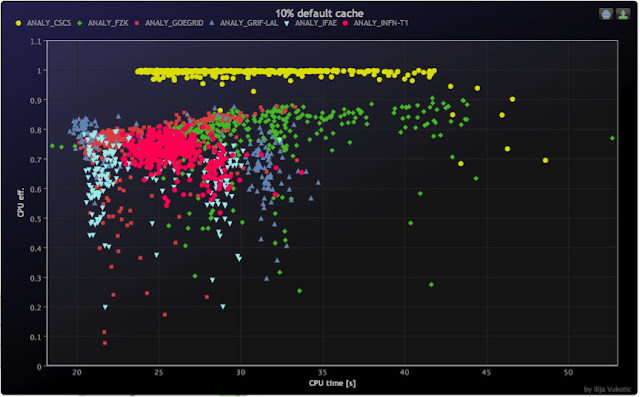
In the test he CSCS carried out and published on February 16, 2012, the engineers load-tested their recently-configured storage system based on IBM's GPFS file system. To their delight, the results showed that they now have the fastest I/O supercomputer among all the ATLAS sites. Accordng to the results, CPU efficiency in this cluster reached "whopping value of 0.99, which means that during the data-intensive computation, there is virtually no I/O wait and all the CPUs were available close to 100% for the ATLAS jobs. This is about 20% better than the next best sites measured with this workload. (See plotted performance in figure below, with yellow one representing the CSCS GPFS system.
What's striking about this speed-up is that there is little hardware change except changing 12 SAS HDD to two SSD (for metadata service). GPFS delivers superb I/O performance over existing nework infrastructure (Mellanox QDR Infiniband), 8 data servrs and 2 metadata servers with these SSD drives.
Another surprise is how the new system outperforms the prevous one based on Lustre file system, a competor of GPFS in the small family of parallel file systems. According to the CSCS blog, GPFS outperforms by far the previous configuration, reaching a speed of 7.2 GB/sec sustained during transfer. Another plus for new architecture -- that pure metadata operations (run command 'ls', scan file system, etc) no longer affect the performance of the system, thanks to the small hardware change to SSD.
In the final analysis, if the we are investing top talents and instrument to reveal the building blocks of God's universe, we should also start to think about how to match up with a smarter computing platform. It's about time, as time is what we cannot afford to lose in the chase of particles.
Links:
Here is the background on the ATLAS dector and its associated data storage and analysis challenge:
ATLAS (A Toroidal LHC Apparatus) is one of the seven particle detector experiments (ALICE, ATLAS, CMS, TOTEM, LHCb, LHCf and MoEDAL) constructed at the Large Hadron Collider (LHC), a new particle accelerator at the European Organization for Nuclear Research (CERN) in Switzerland.
The detector generates unmanageably large amounts of raw data, about 25 megabytes per event (raw; zero suppression reduces this to 1.6 MB) times 23 events per beam crossing, times 40 million beam crossings per second in the center of the detector, for a total of 23 petabyte/second of raw data. Offline event reconstruction is performed on all permanently stored events, turning the pattern of signals from the detector into physics objects, such as jets, photons, and leptons. Grid and HPC are extensively used for event reconstruction, allowing the parallel use of university and laboratory computer networks throughout the world for the CPU-intensive task of reducing large quantities of raw data into a form suitable for physics analysis.
It has been a long journey and struggle for ATLAS analysis sites worldwide to find a balance of cost and performance with their HPC infrastructure, suc as the storage system and architecure that can sustain high demand of data I/O and reliability. As more workloads are outstripping the capability of local hard drive, some sites have started to investiage parallel file systems that can provide fast I/O storage from low-medium cost disks.
In the test he CSCS carried out and published on February 16, 2012, the engineers load-tested their recently-configured storage system based on IBM's GPFS file system. To their delight, the results showed that they now have the fastest I/O supercomputer among all the ATLAS sites. Accordng to the results, CPU efficiency in this cluster reached "whopping value of 0.99, which means that during the data-intensive computation, there is virtually no I/O wait and all the CPUs were available close to 100% for the ATLAS jobs. This is about 20% better than the next best sites measured with this workload. (See plotted performance in figure below, with yellow one representing the CSCS GPFS system.
What's striking about this speed-up is that there is little hardware change except changing 12 SAS HDD to two SSD (for metadata service). GPFS delivers superb I/O performance over existing nework infrastructure (Mellanox QDR Infiniband), 8 data servrs and 2 metadata servers with these SSD drives.
Another surprise is how the new system outperforms the prevous one based on Lustre file system, a competor of GPFS in the small family of parallel file systems. According to the CSCS blog, GPFS outperforms by far the previous configuration, reaching a speed of 7.2 GB/sec sustained during transfer. Another plus for new architecture -- that pure metadata operations (run command 'ls', scan file system, etc) no longer affect the performance of the system, thanks to the small hardware change to SSD.
In the final analysis, if the we are investing top talents and instrument to reveal the building blocks of God's universe, we should also start to think about how to match up with a smarter computing platform. It's about time, as time is what we cannot afford to lose in the chase of particles.
Links:
No comments:
Post a Comment